Mining Data Integration: Rockmapper to datashed Automation
In mining operations, geological data only delivers value when it moves efficiently from field capture into central systems where it can be validated, structured, and used for decision-making. In practice, this transition is often where delays and inconsistencies are introduced.
A common gap exists between field data capture in tools like Rockmapper and data management platforms such as datashed. While data is captured accurately at source, it is typically exported as files and manually processed before being loaded into downstream systems. These manual steps introduce delays, increase duplication risk, and create inconsistencies in data structure and quality.
Understanding the data flow
Rockmapper exports geological data as a ZIP archive containing two primary CSV files:
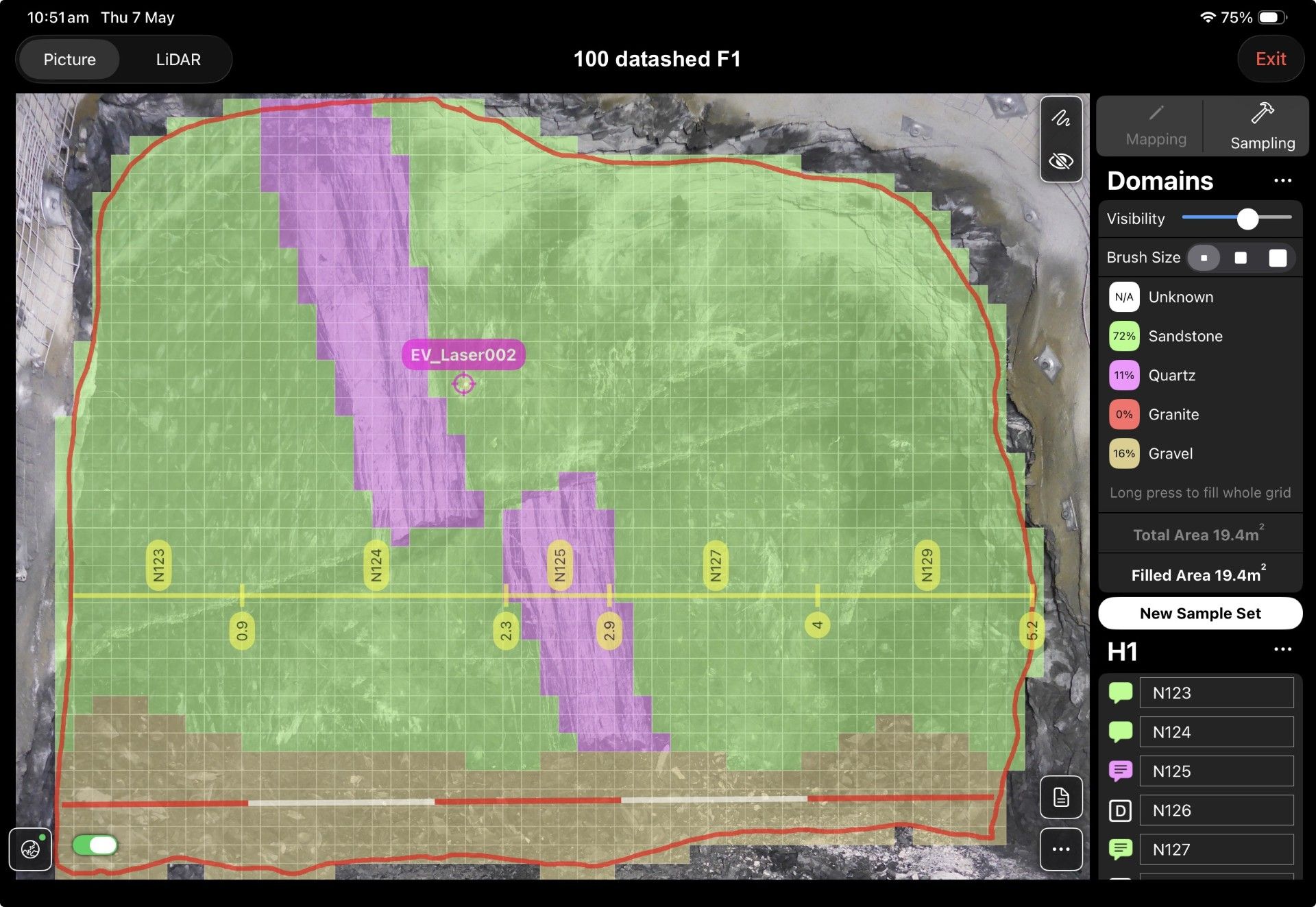
- line_sample_collar.csv – stores collar-level records, including unique collar identifiers, spatial coordinates, and survey metadata used to define the context of each mapped face
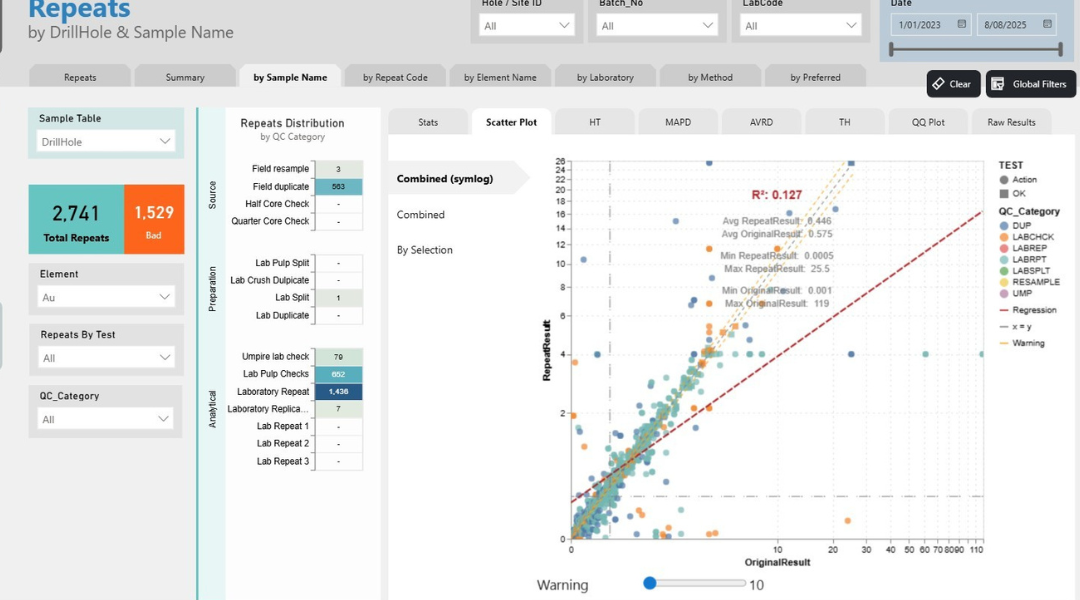
- line_samples.csv – stores sample-level records linked to collar IDs, including lithology, QAQC classifications (e.g. standards, blanks, duplicates), and other attributes required for validation and reporting
Together, these datasets represent a relational structure where collar records provide spatial context for multiple associated sample records. This relationship is critical for maintaining data integrity as information moves into downstream systems.
From manual handling to automated integration
Traditionally, these files are extracted, reviewed, and uploaded manually into systems like datashed. This approach introduces variability in how data is handled and delays its availability for analysis.
The integration replaces this process with an automated, event-driven workflow built using Power Automate.
In this setup, Rockmapper exports are sent directly to a monitored email inbox, which triggers the workflow. The process then:
- Identifies each CSV file based on naming conventions
- Validates file structure and content, including:
- Required columns and naming standards
- Data types and formatting (e.g. numeric fields, dates)
- Referential integrity between collar and sample records
- Routes data into the appropriate transformation pipelines
For example, collar data is directed into face and survey datasets, while sample data is distributed across sample, QAQC, standards, and lithology tables based on attributes such as sample type and classification, before being ingested into datashed.

Why this approach matters
Removing manual handling from this workflow significantly reduces the risk of human error and inconsistent data uploads. Every dataset passes through a standardised validation and transformation process, improving both reliability and traceability.
It also shortens the time between data capture and availability. Geological data that previously required manual preparation becomes accessible almost immediately after export, enabling faster interpretation and decision-making.
In addition, the automated pipeline creates a clear audit trail from file receipt through to ingestion, providing full visibility across the data lifecycle and supporting governance requirements.
Bringing it together
This integration establishes a structured data pipeline between Rockmapper and datashed, replacing manual file handling with a consistent, automated workflow. By enforcing data standards at the point of ingestion and preserving relationships between collar and sample data, it ensures that geological information is both reliable and ready for use as soon as it enters the system.
Rather than relying on manual intervention, the process connects field data capture directly to centralised data management, improving efficiency, consistency and confidence in the data that underpins operational decisions.